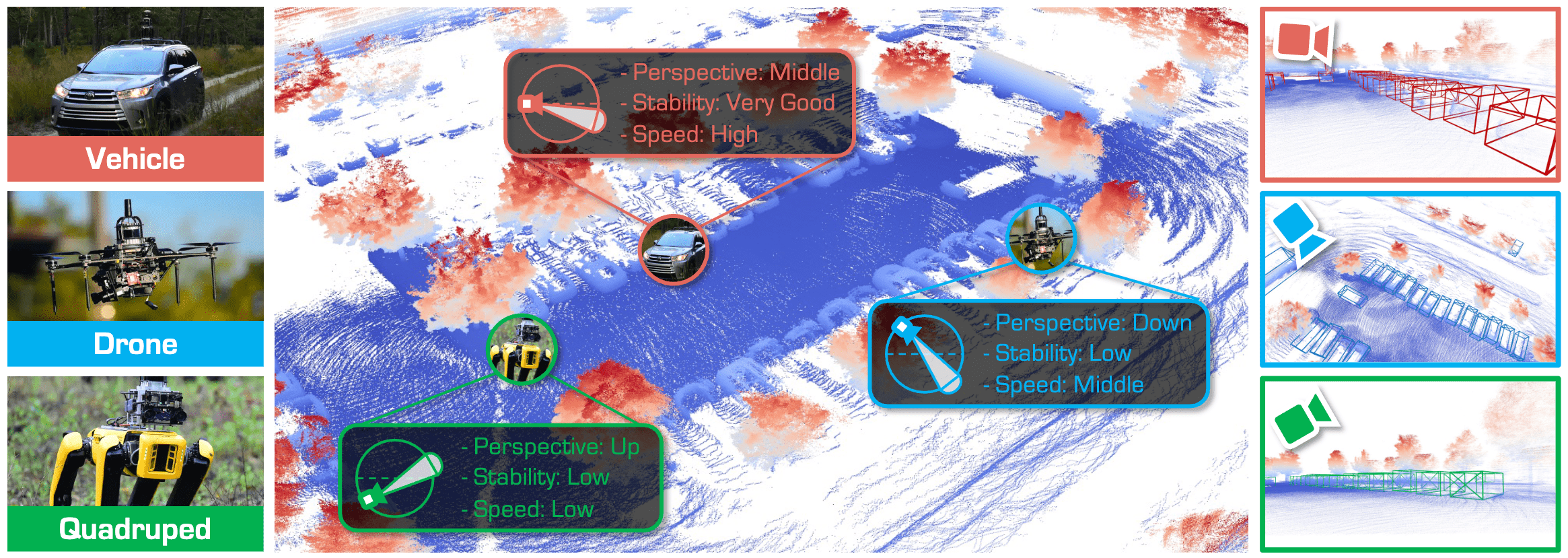
Motivation of Perspective invariant 3D object DETection (Pi3DET). We focus on the practical yet challenging task of 3D object detection from heterogeneous robot platforms: Vehicle, Drone, and Quadruped. To achieve strong generalization, we contribute: (1) The first dataset for multi-platform 3D detection, comprising more than 51K LiDAR frames with over 250K meticulously annotated 3D bounding boxes; (2) An adaptation framework, effectively transferring capabilities from vehicles to other platforms by integrating geometric and feature-level representations; (3) A comprehensive benchmark study of state-of-the-art 3D detectors on cross-platform scenarios.
With the rise of robotics, LiDAR-based 3D object detection has garnered significant attention in both academia and industry. However, existing datasets and methods predominantly focus on vehicle-mounted platforms, leaving other autonomous platforms underexplored. To bridge this gap, we introduce Pi3DET, the first benchmark featuring LiDAR data and 3D bounding box annotations collected from multiple platforms: vehicle, quadruped, and drone, thereby facilitating research in 3D object detection for non-vehicle platforms as well as cross-platform 3D detection. Based on Pi3DET, we propose a novel cross-platform adaptation framework that transfers knowledge from the well-studied vehicle platform to other platforms. This framework achieves perspective-invariant 3D detection through robust alignment at both geometric and feature levels. Additionally, we establish a benchmark to evaluate the resilience and robustness of current 3D detectors in cross-platform scenarios, providing valuable insights for developing adaptive 3D perception systems. Extensive experiments validate the effectiveness of our approach on challenging cross-platform tasks, demonstrating substantial gains over existing adaptation methods. We hope this work paves the way for generalizable and unified 3D perception system across diverse and complex environments. Our Pi3DET dataset, cross-platform benchmark suite, and annotation toolkit have been made publicly available.
Summary of LiDAR-based 3D object detection datasets.
We compare key aspects from 1robot platforms, 2scale, 3sensor setups, 4temporal (Temp.), 5multi-conditions, etc.
To our knowledge, Pi3DET stands out as the first work to feature multi-platform 3D detection from
![]() Vehicle,
Vehicle,
![]() Drone, and
Drone, and
![]() Quadruped, with fine-grained 3D bounding box annotations, conditions, and practical use cases.
Quadruped, with fine-grained 3D bounding box annotations, conditions, and practical use cases.
| Dataset | Venue | Platform | # of Frames |
LiDAR Setup |
Temp. | Freq. (Hz) |
Condition | Other Sensors Supported | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Vehicle | Drone | Quad |
|
|
|||||||
| KITTI | CVPR'12 | ✓ | ✗ | ✗ | 14,999 | 1x64 | No | - | ✓ | ✗ |
|
| ApolloScape | TPAMI'18 | ✓ | ✗ | ✗ | 143,906 | 1x64 | Yes | 2 | ✓ | ✓ |
|
| Waymo Open | CVPR'19 | ✓ | ✗ | ✗ | 198,000 | 1x64+4x16 | Yes | 10 | ✓ | ✓ |
|
| nuScenes | CVPR'20 | ✓ | ✗ | ✗ | 35,149 | 1x32 | Yes | 2 | ✓ | ✓ |
|
| ONCE | arXiv'21 | ✓ | ✗ | ✗ | ~1 M | 1x40 | No | 2 | ✓ | ✓ |
|
| Argoverse 2 | NeurIPS'21 | ✓ | ✗ | ✗ | ~6 M | 2x32 | Yes | 10 | ✓ | ✗ |
|
| aiMotive | ICLRW'23 | ✓ | ✗ | ✗ | 26,583 | 1x64 | Yes | 10 | ✓ | ✓ |
|
| Zenseact Open | ICCV'23 | ✓ | ✗ | ✗ | ~100 K | 1x128+4x16 | Yes | 1 | ✓ | ✓ |
|
| MAN TruckScenes | NeurIPS'24 | ✓ | ✗ | ✗ | ~30 K | 6x64 | Yes | 2 | ✓ | ✓ |
|
| AeroCollab3D | TGRS'24 | ✗ | ✓ | ✗ | 3,200 | N/A | No | - | ✓ | ✗ |
|
| Pi3DET | Ours | ✓ | ✓ | ✓ | 51,545 | 1x64 | Yes | 10 | ✓ | ✓ |
|
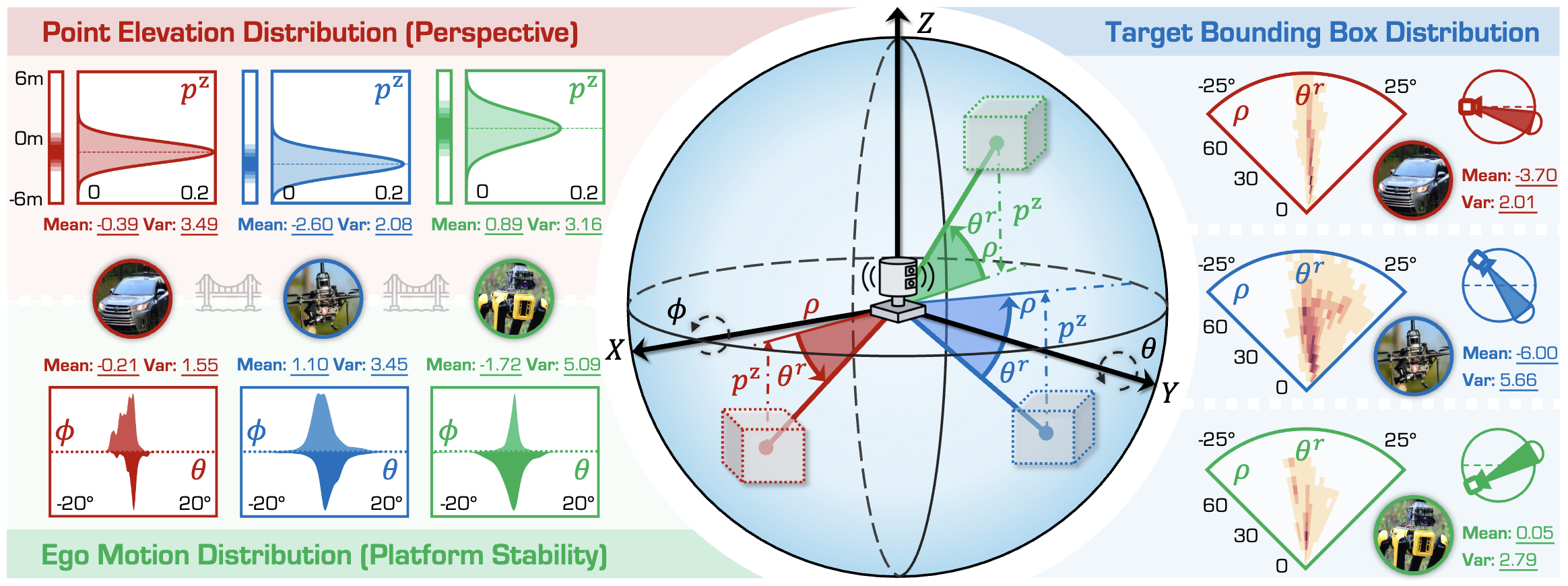
Figure: Analysis of perspective differences across three robot platforms. We present the statistics of point elevation distribution (upper-left), ego motion distribution (bottom-left), and target bounding box distribution (right), along with means and variances for each platform's data.
We use different colors to denote different platforms for simplicity, i.e.,
![]() Vehicle,
Vehicle,
![]() Drone, and
Drone, and
![]() Quadruped.
Best viewed in colors.
Quadruped.
Best viewed in colors.


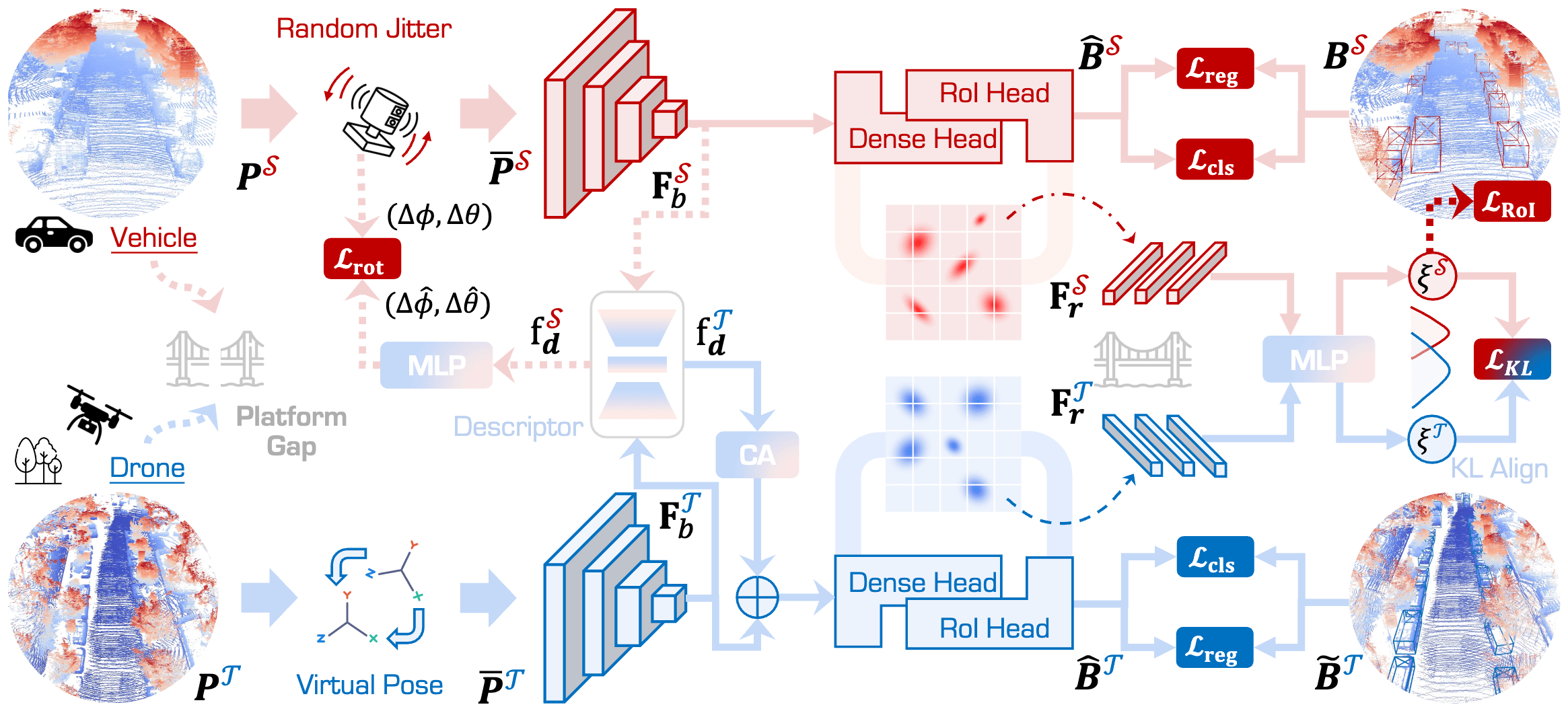
Framework Overview. The proposed Pi3DET-Net consists of two main stages: Pre-Adaption (PA) and Knowledge-Adaption (KA), aiming at bridging the gap across heterogeneous robot platforms through alignment at both geometric (see Section: geometry alignment) and feature levels (see Section: feature alignment). On the geometric side, PA employs Random Platform Jitter to enhance robustness against ego-motion variations, while KA uses Virtual Platform Pose to simulate source-like viewpoints to achieve bidirectional geometric alignment across platforms. On the feature side, Pi3DET-Net further incorporates KL Probabilistic Feature Alignment to align target features with the source space, along with a Geometry-Aware Transformation Descriptor to correct global transformations across platforms.
We report the average precision (AP) in “BEV / 3D” at IoU thresholds of 0.7 and 0.5. Symbol ‡ denotes algorithms w.o. ROS. All scores are given in percentage (%). “–” denotes code not available. The Best and Second Best scores under each metric are highlighted in red and blue, respectively.
| # | Method |
|
|
Average | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PV-RCNN | Voxel RCNN | PV-RCNN | Voxel RCNN | ||||||||
| AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | AP@0.7 | AP@0.5 | ||
| nuScenes | Source Platform | 43.40 / 33.55 | 44.86 / 42.84 | 43.25 / 33.74 | 45.62 / 43.32 | 50.91 / 35.26 | 57.73 / 50.24 | 50.15 / 29.41 | 57.10 / 49.10 | 46.93 / 32.99 | 51.33 / 46.34 |
| ST3D | 55.40 / 42.02 | 59.59 / 54.75 | 44.54 / 35.96 | 45.81 / 44.38 | 65.05 / 40.01 | 68.93 / 64.09 | 54.62 / 33.79 | 58.45 / 52.89 | 54.90 / 37.95 | 58.20 / 54.03 | |
| ST3D‡ | 55.68 / 44.50 | 59.32 / 55.32 | 45.01 / 37.13 | 46.73 / 45.45 | 65.40 / 43.63 | 69.24 / 64.88 | 55.23 / 36.51 | 59.30 / 54.23 | 55.33 / 40.44 | 58.65 / 54.97 | |
| ST3D++ | 55.76 / 43.51 | 59.93 / 55.28 | 45.56 / 36.97 | 47.28 / 45.84 | 60.91 / 40.09 | 68.96 / 59.96 | 57.02 / 37.52 | 61.30 / 55.43 | 54.81 / 39.52 | 59.37 / 54.13 | |
| ST3D++‡ | 54.96 / 40.81 | 60.47 / 54.65 | 45.69 / 36.76 | 48.30 / 46.05 | 65.50 / 43.46 | 68.99 / 64.62 | 55.92 / 39.46 | 59.93 / 55.19 | 55.52 / 40.12 | 59.42 / 55.13 | |
| REDB | 52.43 / 41.34 | 57.12 / 54.18 | – / – | – / – | 65.31 / 39.19 | 68.74 / 64.13 | – / – | – / – | – / – | – / – | |
| MS3D++ | 56.24 / 43.20 | 60.88 / 56.13 | 51.50 / 40.14 | 56.03 / 53.86 | 66.99 / 43.76 | 69.87 / 65.85 | 62.68 / 38.26 | 68.34 / 61.09 | 59.35 / 41.34 | 63.78 / 59.23 | |
| Pi3DET‑Net | 56.80 / 46.36 | 61.54 / 57.20 | 54.85 / 42.38 | 57.41 / 55.54 | 65.43 / 45.94 | 69.24 / 65.87 | 65.63 / 44.62 | 72.05 / 63.83 | 60.68 / 44.83 | 65.06 / 60.61 | |
| Target Platform | 54.15 / 40.24 | 58.63 / 54.96 | 54.90 / 39.74 | 56.46 / 55.19 | 67.67 / 46.11 | 70.04 / 66.14 | 68.52 / 46.53 | 70.67 / 61.42 | 61.31 / 43.16 | 63.95 / 59.43 | |
| Pi3DET (Vehicle) | Source Platform | 38.61 / 26.84 | 40.64 / 39.22 | 43.95 / 31.24 | 48.22 / 44.17 | 57.29 / 36.62 | 58.92 / 56.19 | 52.85 / 37.96 | 61.10 / 52.47 | 48.17 / 33.16 | 52.22 / 48.01 |
| ST3D | 49.29 / 38.69 | 51.02 / 49.71 | 47.70 / 37.91 | 48.07 / 47.59 | 60.17 / 33.01 | 62.84 / 54.51 | 53.79 / 40.18 | 65.29 / 53.40 | 52.74 / 37.45 | 56.81 / 51.30 | |
| ST3D‡ | 47.89 / 38.07 | 49.50 / 48.23 | 47.01 / 41.85 | 54.01 / 53.46 | 60.67 / 33.27 | 62.98 / 54.61 | 53.85 / 40.02 | 62.70 / 53.08 | 52.35 / 38.30 | 57.30 / 52.34 | |
| ST3D++ | 46.05 / 37.22 | 49.33 / 47.84 | 48.52 / 37.84 | 55.82 / 48.53 | 60.04 / 33.98 | 62.71 / 54.13 | 53.71 / 39.94 | 62.43 / 53.20 | 52.08 / 37.24 | 57.57 / 50.92 | |
| ST3D++‡ | 45.14 / 35.70 | 46.94 / 45.37 | 47.52 / 37.13 | 54.37 / 47.63 | 64.15 / 34.20 | 63.81 / 55.44 | 53.64 / 40.27 | 62.43 / 53.10 | 52.61 / 36.83 | 56.89 / 50.38 | |
| REDB | 46.74 / 38.47 | 50.29 / 49.54 | – / – | – / – | 61.57 / 34.05 | 63.22 / 54.07 | – / – | – / – | – / – | – / – | |
| MS3D++ | 53.66 / 40.66 | 55.21 / 53.78 | 53.65 / 41.93 | 54.69 / 54.00 | 66.05 / 41.17 | 67.80 / 63.26 | 53.85 / 40.91 | 62.87 / 53.44 | 56.80 / 41.17 | 60.14 / 56.12 | |
| Pi3DET‑Net | 56.19 / 44.28 | 60.35 / 56.20 | 55.54 / 45.18 | 59.48 / 58.90 | 66.26 / 44.47 | 68.25 / 63.36 | 67.87 / 46.83 | 69.95 / 66.26 | 61.47 / 45.19 | 64.51 / 61.18 | |
| Target Platform | 54.15 / 40.24 | 58.63 / 54.96 | 54.90 / 39.74 | 56.46 / 55.19 | 67.67 / 46.11 | 70.04 / 66.14 | 68.52 / 46.53 | 70.67 / 61.42 | 61.31 / 43.16 | 63.95 / 59.43 | |
| Combined All | 58.21 / 46.27 | 62.18 / 59.67 | 60.96 / 48.15 | 63.04 / 61.04 | 68.44 / 48.19 | 71.11 / 68.24 | 68.90 / 48.88 | 72.55 / 69.18 | 64.13 / 47.87 | 67.22 / 64.53 | |
@inproceedings{liang2025pi3det,
title = {Perspective-Invariant 3D Object Detection},
author = {Ao Liang and Lingdong Kong and Dongyue Lu and Youquan Liu and Jian Fang and Huaici Zhao and Wei Tsang Ooi},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2025},
} Perspective-Invariant 3D Object Detection
Perspective-Invariant 3D Object Detection